Sound Classification Using an IIR Filter
Tanya Datta
Dec 18, 2024
Hi, I'm Tanya, a new member of C2S2's project management subteam. As someone intrigued by the intersection of hardware and software, I have attended some of the software subteam's meetings to learn more about their ongoing projects. This semester, the team is working on an innovative method to classify scrub jay calls.
Traditionally, a matched-filter is used to determine whether an audio file contains a scrub jay call. However, the software subteam wanted to explore alternative techniques that might offer better accuracy or flexibility. They consulted with Professor Hunter Adams to brainstorm a new approach: approximating a derivative of each call frequency by breaking the call into segments and analyzing these segments with Infinite Impulse Response (IIR) filters.
An IIR filter is a type of digital filter that processes an input signal using both the current input and past outputs. The goal was to apply multiple IIR filters to identify the upward frequency trend characteristic of scrub jay calls. By doing so, the team hoped to classify the calls with greater precision.
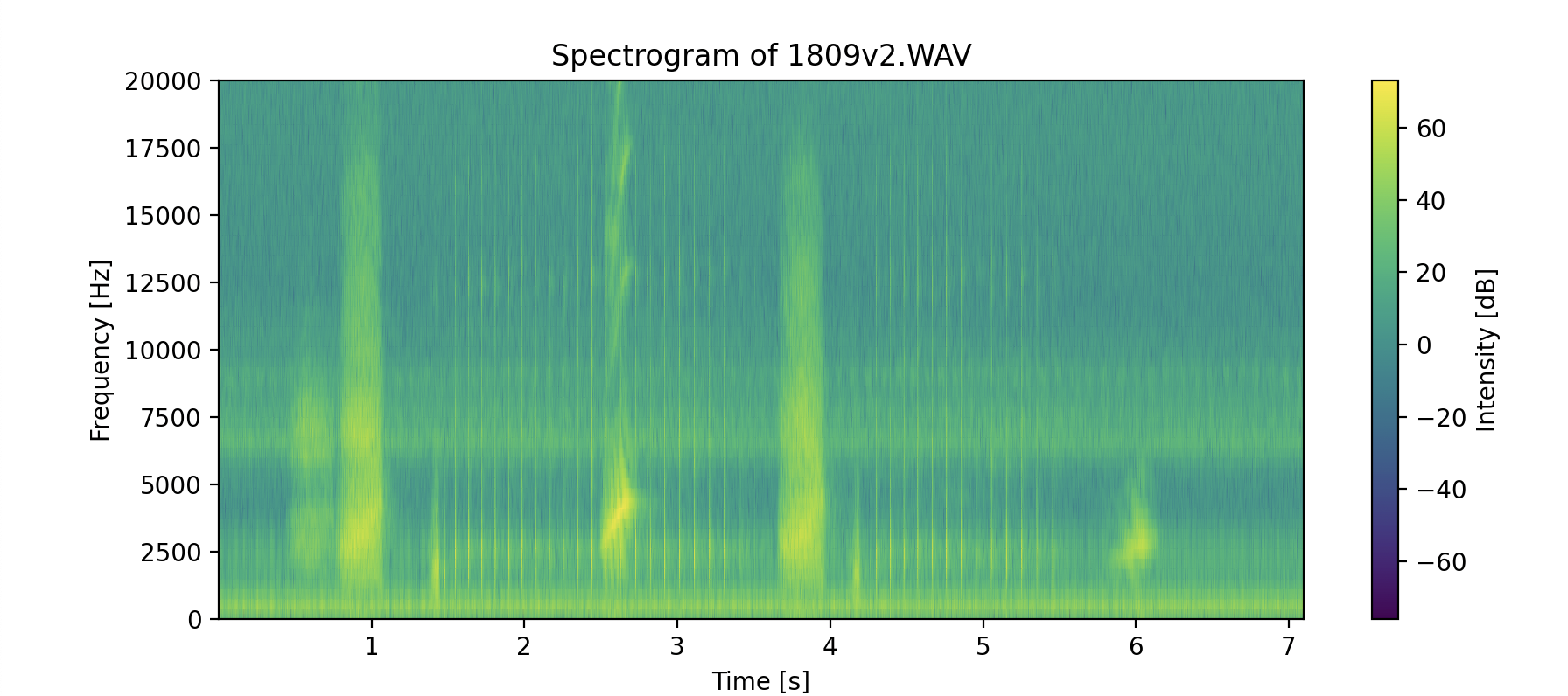
A spectrogram of the frequency of the scrub jay calls over time
While the concept offers great promise, they ran into a few issues when implementing these filters. For one, there were inconsistent slopes within the provided data samples, thus it was difficult to accurately and consistently identify upward frequency trends. In addition, there are inconsistencies in the ranges of the frequencies, as well as the intensity and duration of them. Due to these issues with the data, it is difficult to generalize the filtering process.
The software team tried different approaches to address these inconsistencies. For one, they normalized the intensity to account for the fact the scrub jay calls were recorded at different volumes. However, even after normalization, the slopes were still different between the clips. They then took averages from the sample data, but there were very small time ranges within the data (~0.2s) but they had a fairly large frequency range (~2200 Hz). This makes the data extremely sensitive to slight differences in sampling, leading to inconsistent results. Additionally, an approach that based frequency ranges off of individual samples would lead to overclassification.
Moving forward, the software team will conduct further testing to see what parameters should be modified in order to minimize false positives and negatives. In addition to fine tuning these parameters, instead of classifying sounds based off of the slopes, they will classify based off of the ‘outline’ of the slopes. This will account for the aforementioned variations in the data. They also are coordinating with project management to receive more data samples from our campus partner so they have a wider range on what to train their classifier on.
Classifier output
Overall, it has been exciting learning about the new developments and strides the software team is making and how they are overcoming their various challenges and adapting to the circumstances they are in!